模仿者動態(replicator dynamic,又稱為複製動態)是學者研究最多的社會學習模型。模仿者動態模型假設個人採取一項行動的機率,等於行動報酬和流行程度的乘積。

圖片來源:Unsplash
編按:一般來說,團體成員的行為,往往傾向跟隨群體。當發現自己的行為、意見與團體出現分歧,便會感受到壓力,促使成員趨向於與群體一致。這樣的「從眾行為」究竟從何而來?
以下為《多模型思維》作者裴吉應用數學模型,討論人們為何總是模仿最多人採用的行動或策略:
有限選項中,人們會學習選擇最佳選項。群體人數無限的模仿者動態模型,會收斂到整個群體都選擇最佳選項。
模仿者動態(replicator dynamic,又稱為複製動態)是學者研究最多的社會學習模型。模仿者動態模型假設個人採取一項行動的機率,等於行動報酬和流行程度的乘積。行動報酬可以想像為獎勵效應(reward effect),流行程度則為從眾效應(conformity effect)。
模仿者動態模型通常會先假設群體的數量無限,下一步則是把採取的行動描述為所有選項的機率分布。在模仿者動態模型的標準結構中,時間以離散方式(不連續的方式)前進,以便藉由機率分布的改變,來呈現學習現象。
舉個例子來說明。我們考量某個家長社群,所有家長都必須在蘋果煎餅、香蕉煎餅和巧克力煎餅之間做選擇。假設所有小孩都有相同偏好,而三種煎餅分別可產生20、10和5的報酬。假設一開始10%的家長做了蘋果煎餅、70%的家長做了香蕉煎餅、20%的家長做了巧克力煎餅,則平均報酬會等於10。應用模仿者公式後,在第二週期選擇這三種選項的機率,各如下表所示:
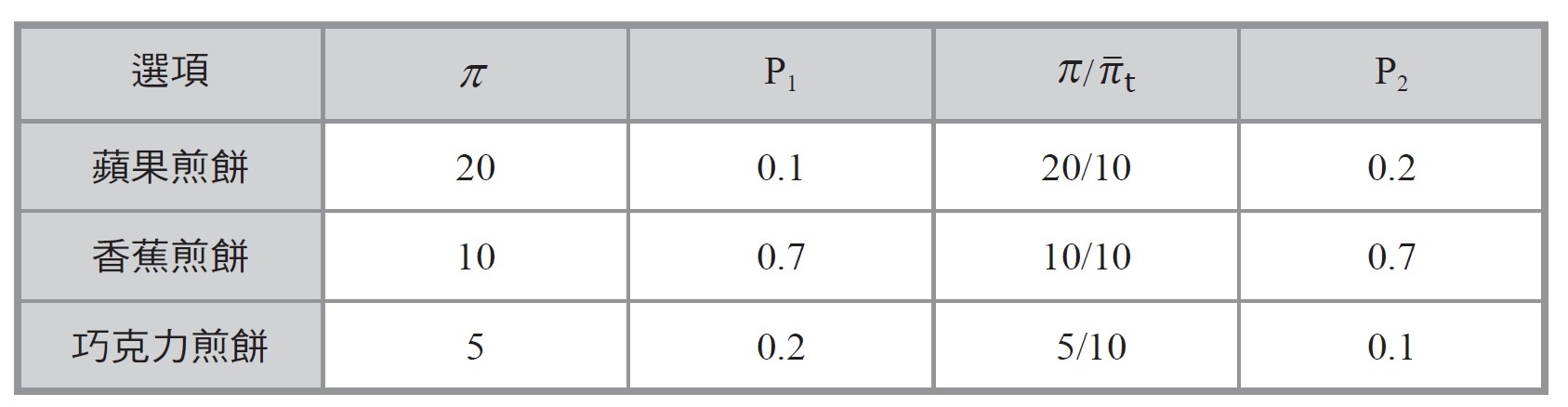
在第二週期選擇做蘋果煎餅的家長,會是第一週期的兩倍,這是因為蘋果煎餅的報酬為平均報酬的兩倍;而做巧克力煎餅的家長人數則只剩一半,因為做巧克力煎餅的報酬為平均報酬的一半。至於做香蕉煎餅的報酬,因為與平均報酬相等,所以做香蕉煎餅的家長人數維持不變。加總三種選項的改變,會發現平均報酬增加為11.5。
如同先前提到,模仿者動態模型包含從眾效應(愈受歡迎的選項,愈容易被模仿)和獎勵效應。長期下來,主要是獎勵效應影響最終結果,因為高報酬選項的選擇人數占比,相對於低報酬選項會不斷成長。模仿者動態模型中,平均報酬的作用就類似強化學習模型中,會不斷調整到平均報酬的激勵水準。兩者唯一差異在於:模仿者動態模型中為計算群體的平均報酬,而強化學習模型中的激勵水準等於個人的平均報酬。此外,由於群體提供了更大的樣本,路徑依賴對於模仿者動態的影響,會比強化學習還低。
建構模仿者動態模型時,我們假設初始狀態中的每個選項都有人選擇。由於最高報酬的選項永遠會產生高於平均的報酬,而且選擇最高報酬選項的人數也會在各週期逐漸增加,最終,模仿者動態會收斂至整個群體都選擇了最佳選項。 因此,在學習最佳選項的設定下,無論個人學習或社會學習,都會收斂到最高報酬的選項。
【書籍資訊】
《多模型思維》
 出版日期:2021.01.28
出版日期:2021.01.28